Graduate School Statement of Purpose
January 14th, 2024/
Like many kids, I have always been fascinated by the magic of animated movies and video games. The sheer feeling of wonder, awe, and thrill after watching an inspiring Disney movie or experiencing a victorious moment in my favorite video game is what initially sparked my curiosity for computer graphics. That passion has stuck with me ever since. However, more recently, I've discovered another enthralling fascination for artificial intelligence, this time emerged from witnessing the rapid innovation of remarkable new technologies that promise enormous potential for driving progress. I am inspired by what artificial intelligence can achieve today and am eager to delve deeper into this field to contribute to advancing its capabilities and play a part in shaping this transformative period in history. I want to pursue a Master’s degree in computer science to broaden my expertise in these specialized areas that I am so passionate about and to prepare myself to embark on the development of complex projects and new technologies that solve important problems and make a positive impact on the world. I am driven by the hope that one day my work will help people and create in others the same magical feeling that I first experienced in my childhood from movies and video games. ...
Throughout my undergraduate journey seeking dual bachelor's degrees at Purdue, I've engaged in exciting and challenging coursework across my areas of focus. Last spring, I enrolled in CS334: Fundamentals of Computer Graphics, where I especially enjoyed discussions about illumination and shading, physically based simulations using GPUs, optimizations with spatial data structures and hierarchies, procedural modeling, and deep visual computing. As my final project for the class, I developed a particle-based fluid simulation from scratch to mimic realistic liquid behavior. After the course, I reached out to Prof. Aliaga to further my involvement, and he extended me an invitation to attend Graphics Talks conducted by graduate students and faculty at the Computer Graphics and Visualization Laboratory (CGVLAB). Attending these talks gave me insight on the type of projects that the students involve in, and it confirmed my interest in pursuing further education and conducting research in computer graphics.The emergence of Artificial Intelligence captivated me. Participating in an NVIDIA Deep Learning workshop in 2022 and taking a Data Mining & Machine Learning elective course led me to add Machine Intelligence as a concentration in my degree. I believe this field is still largely untapped and the vast possibilities for discovery excite me; there is so much more to learn and create. Moreover, the immense potential of AI to impact society emphasizes the crucial need for ethical considerations. Drawing from my leadership roles, I am eager to engage in projects and research in this domain while advocating for ethical approaches in AI development.
I also believe my teaching experience reinforces my qualifications and motivation for graduate school. I served as an undergraduate teaching assistant during 3 semesters for CS177, one of Purdue’s largest introductory programming courses, and I worked as an academic tutor for smaller groups and individuals in 100 and 200-level mathematics and computer science courses. Assisting over 30 students per semester by leading labs, office hours, and grading, I improved my skills in communicating complex technical concepts clearly, while reinforcing my own expertise. I find joy and fulfillment in helping others grasp challenging concepts, and I intend to continue my teaching efforts in graduate school through teaching assistantships or mentorship programs to support and connect with students from diverse backgrounds.
As a Mexican citizen and active resident, I recognize how rare this opportunity is to pursue a graduate degree from a highly ranked American university like Carnegie Mellon. According to the Organisation for Economic Co-operation and Development (OECD), approximately 0.7% of all Mexicans earn a graduate degree, and only about 1% of college-aged students from Mexico get the chance to study abroad (NAFSA). These numbers are very low compared to other OECD countries, and they highlight the unique privilege and opportunity I have. Yet I refuse to allow statistics or stereotypes to limit my potential. Through hard work, invaluable help, and consistent effort across challenging courses and projects, I have put myself in a position to achieve this dream that many of my talented peers back home could not actively chase. I now hope to take full advantage of Carnegie Mellon’s exceptional academics and research community to prepare myself to drive advancements in emerging technology fields. By succeeding in this prestigious program as a Mexican computer scientist, I aim to set an example for other minority students that their backgrounds need not restrict their ambitions and that all goals are attainable when you combine motivation with a stubborn persistence to overcome obstacles.
Thank you for your thoughtful consideration of my application.
{C} Speller Implementation | CS50 Problem Set 5
July 21st, 2020/
In CS50's Week 5 Problem Set, your task is to implement a spell-checker using a dictionary of words and a hash table. "The challenge ahead is to implement the fastest spell checker you can! By 'fastest,' though, we’re talking actual 'wall-clock,' not asymptotic, time". Initially, they provide you with a program that’s designed to spell-check a file after loading a dictionary of words from disk into memory. Unfortunately, they didn’t quite get around to implementing the loading part. Or the checking part. Both (and a bit more) they leave to you! Here's what I did: ...
In the program that they provide you with, there are three main files, plus some dictionaries to work with and some sample texts and keys to test your code. First is speller.c, a program that implements a spell-checker, outputting a list of all the words misspelled in a file, plus some statistics on the number of words and the time to run each part of your program. The spell-checker works by taking each word in an inputted file, running it through your program, and checking if that word with its specific spelling is found in a hashed dictionary. That dictionary, meanwhile, is implemented in a file called dictionary.c. (As programs get more complex, it’s often convenient to break them into multiple files.) The prototypes for the functions therein, meanwhile, are defined not in dictionary.c itself but in dictionary.h instead. That way, both speller.c and dictionary.c can #include the file. Here's a more detailed explanation of the problem by CS50's own Brian Yu: In short, you need to implement 5 functions: a load function, to load the contents of the dictionary into memory; a hash function (perhaps the most important part of the problem), to perform some sort of operation on a word to determine its hash code, that in this case is going to be the index of our hash table in which we are going to insert that specific word; a size function, to count the number of words in the dictionary; a check function, to determine if a word is misspelled or not using, again, the hash function; and an unload function, to free all the memory previously allocated for our data structure. We'll review my implementation for each of these functions:- Preparations.-
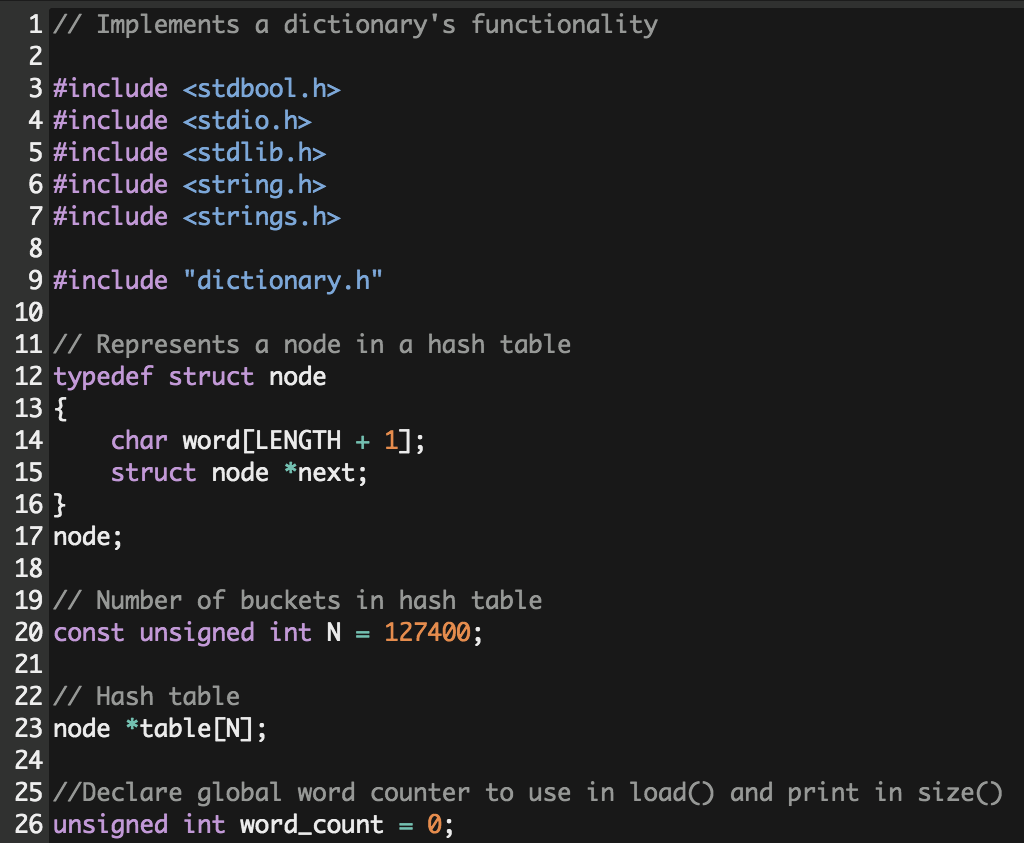
- Load() .-
 To do this, I used a while loop that uses fscanf to copy from the dictionary (*d), each word (%s for string), into our word_array
as long as we have not reached the end of the file. Once inside the loop, we call a secondary function to create a new node with
that word in our hash table, initializing its *next pointer to NULL. Then, we run our node's word through the hash function
(later explained) to get the specific index of our hash table in which we'll insert the node. Now that the node is created and we
know where we should put it, we set the *next pointer of our node to point to the head of the list at the desired index, and then
change the head of the list to be the current node. This will take care of keeping everything connected, creating a linked list in
the indexes where multiple nodes collide. Finally, we increment the word count after we've added each word. When we're finished, we
close the dictionary file and return true if no errors where found.
To do this, I used a while loop that uses fscanf to copy from the dictionary (*d), each word (%s for string), into our word_array
as long as we have not reached the end of the file. Once inside the loop, we call a secondary function to create a new node with
that word in our hash table, initializing its *next pointer to NULL. Then, we run our node's word through the hash function
(later explained) to get the specific index of our hash table in which we'll insert the node. Now that the node is created and we
know where we should put it, we set the *next pointer of our node to point to the head of the list at the desired index, and then
change the head of the list to be the current node. This will take care of keeping everything connected, creating a linked list in
the indexes where multiple nodes collide. Finally, we increment the word count after we've added each word. When we're finished, we
close the dictionary file and return true if no errors where found.
- Size() .-

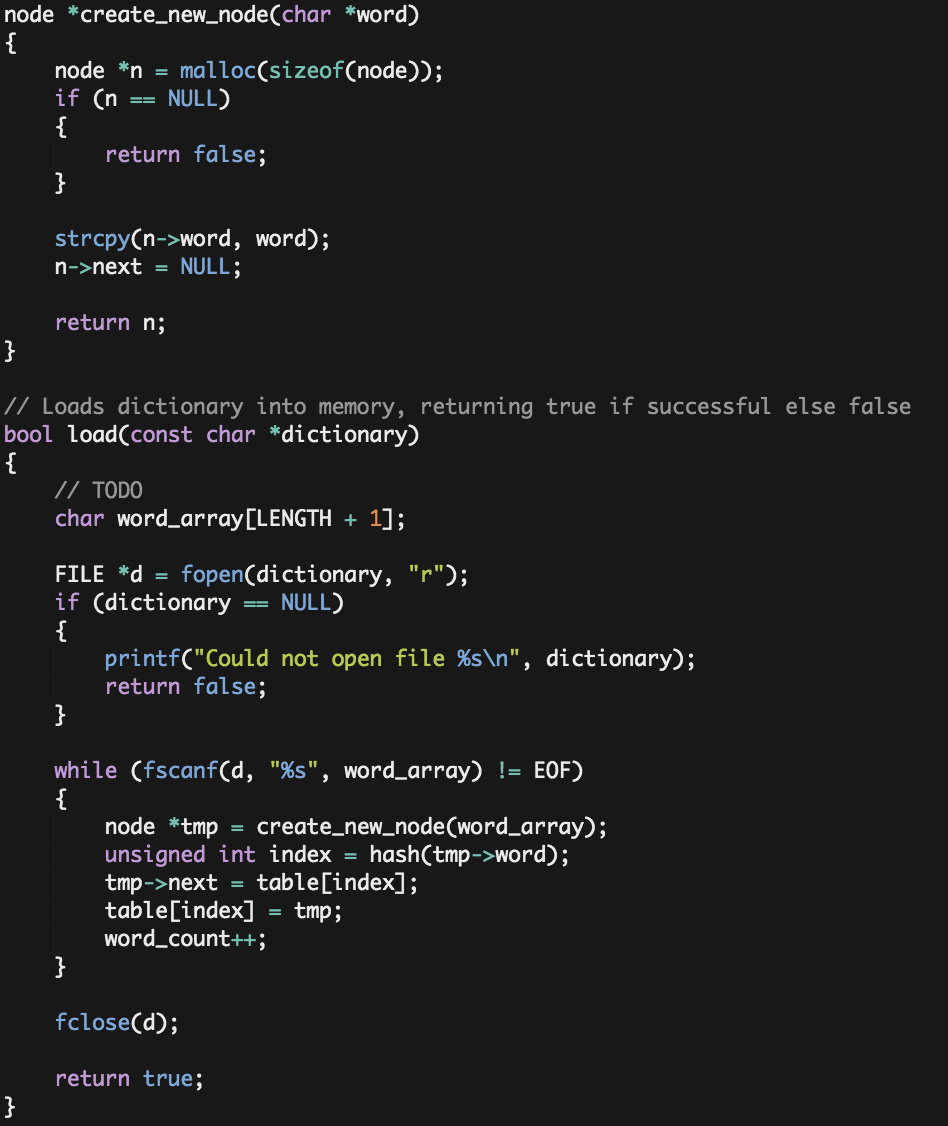
- Hash() .-
What I first though about was to take the ascii sum for all the letters in the word and substract 97 from that number, so that the smallest-value word ("a") would get the index 0. Since the largest allowed length for a word is 45 characters and the largest ascii value for a letter (z) is 122, that would give 5490 buckets for our hash table, but a word with 45 z's in a row seemed a bit excessive, so I decided that 4900 buckets was enough. While this seemed to perform decently, the running time wasn't as fast as I would want it to be and we were still getting many collisions, so I took that same value and multiplied it by the index of the first letter of the word (by index I mean 0 for a, 1 for b, etc...). Although this did make the program a little faster, some new collisions were also created. To avoid these new collisions and get even better results, I twitched the operation a little bit and, in addition to multiplying by the index of the first letter, I multiplied that index by 4900, avoiding any new collisions and spreading out the new values. Yes, this resulted in a lot more buckets (127,400 to be exact) and a lot of empty ones, but the performance was much greater, even as fast as the CS50's staff implementation almost, so I decided the memory wasted was worth the price.
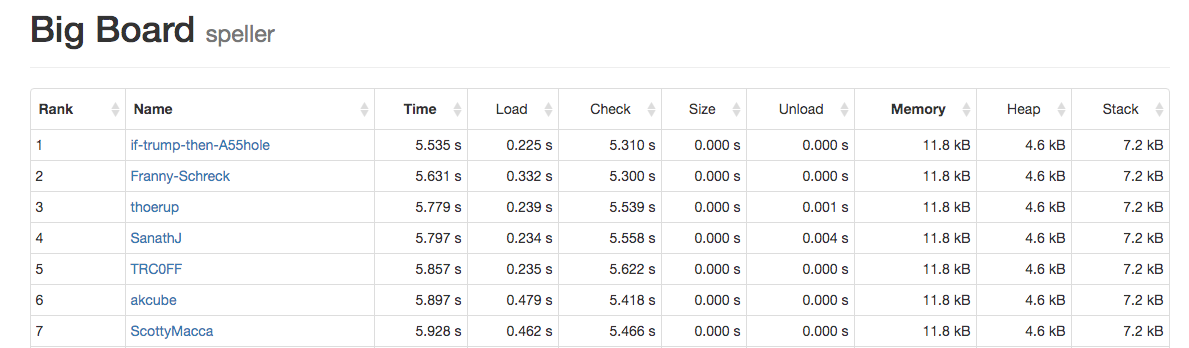
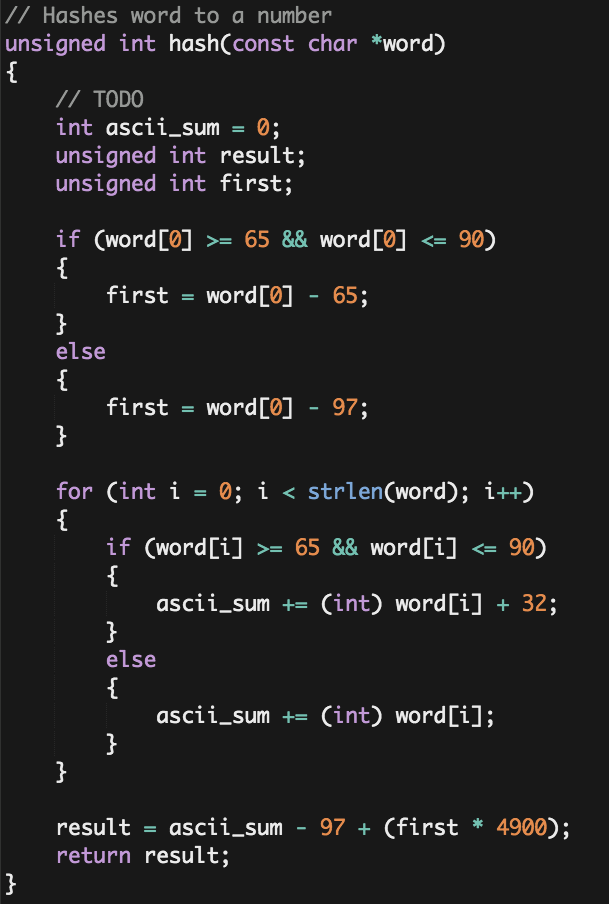 These are some examples of my program's running time compared to the staff's solution:
These are some examples of my program's running time compared to the staff's solution:
| Sample Text | My Implementation | Staff's Solution |
|---|---|---|
| Bible | 0.55s | 0.52s |
| Cat | 0.03s | 0.04s |
| La la land | 0.05s | 0.06s |
| Constitution | 0.04s | 0.04s |
| Shakespeare | 0.66s | 0.63s |
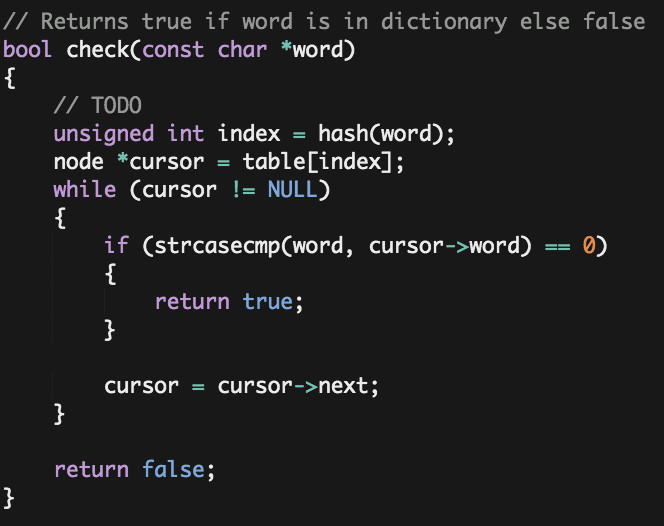
- Check() .-
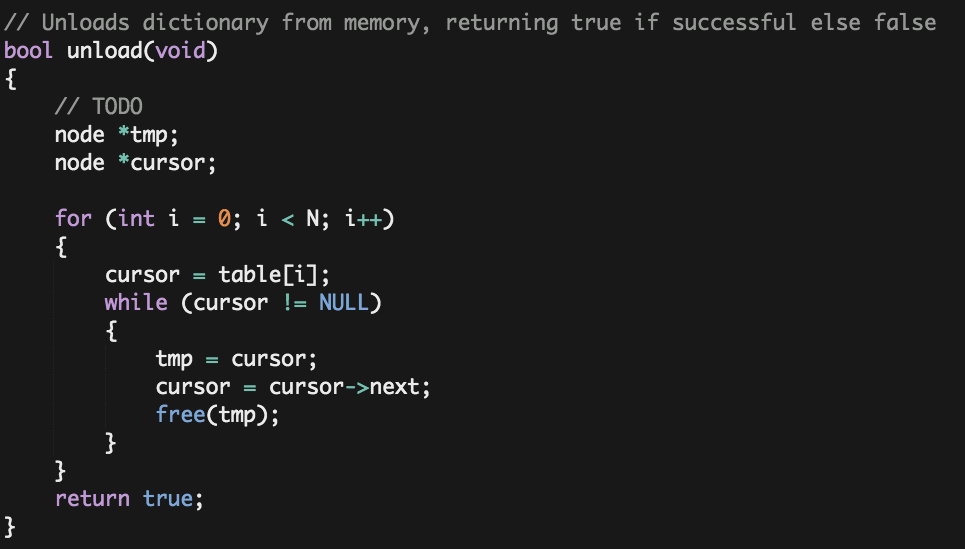
- Unload() .-
- Conclusion.-
Until Next Time, this was Speller.

Python x Tkinter Elevator Animation
July 17th, 2020/
I developed this small project back in December, while on vacation, because I had just found out about Graphical User Interfaces (or GUIs for short) and I wanted to get my head around how to use them, so after I found out that one of the most popular GUI modules was Tkinter and learning the basics of it, one of my first ideas to test it was to make a small interactive animation of an elevator in which you could click the buttons for each floor and watch the simple elevator drawing move to your selected floor in real time. Here's what I did: ...
I started by downloading and importing Tkinter, creating a window for the GUI and styling it with basic geometry and colors. I then went on to learn how to create basic lines and shapes, along with text elements, buttons, labels, canvas, and more simple features to include inside my interface's window.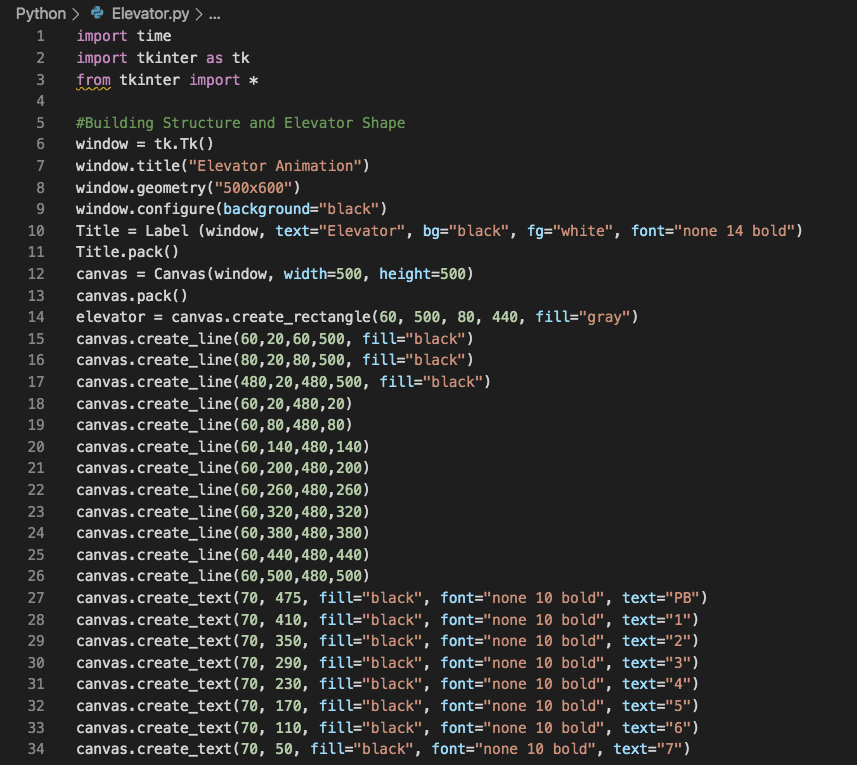 This took care of the "design" of the window, title, and a drawing of a building with a small elevator in it and multiple floors
from PB (more commonly L for Lobby) to a 7th floor. The second part was the coding of the buttons for every floor. For this,
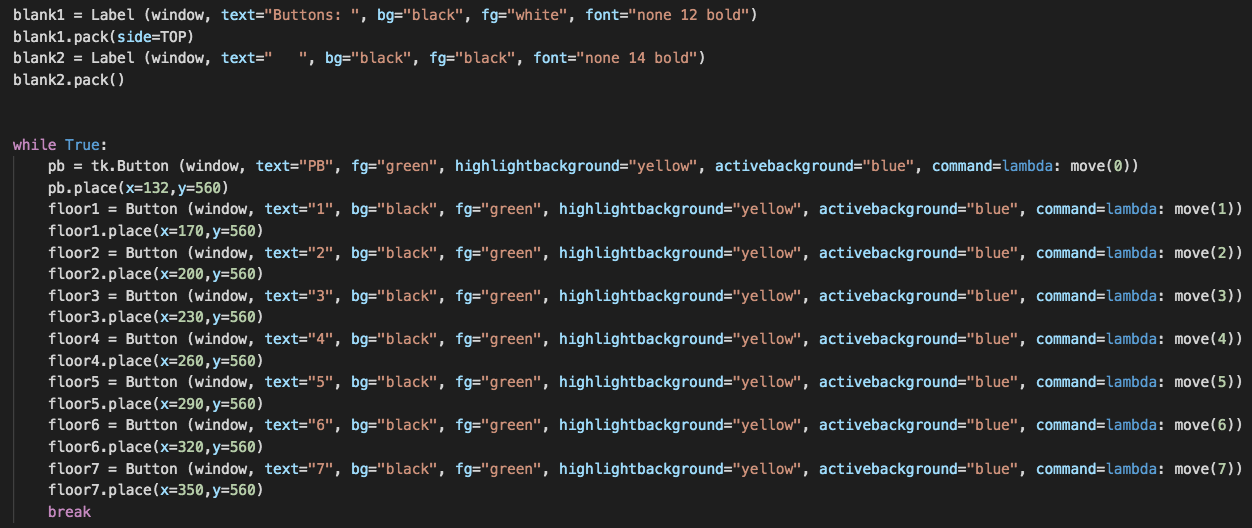
I created a small space at the bottom of the window labeled "Buttons", where I laid out 8 evenly-spaced-out yellow buttons.
This took care of the "design" of the window, title, and a drawing of a building with a small elevator in it and multiple floors
from PB (more commonly L for Lobby) to a 7th floor. The second part was the coding of the buttons for every floor. For this,
I created a small space at the bottom of the window labeled "Buttons", where I laid out 8 evenly-spaced-out yellow buttons. In Tkinter, buttons take a "command" parameter to specify an action to perform whenever that specific button is clicked. However, when running my program, I found that the elevator started moving under the command of every button without the user even pressing on a button! To fix this, I found that you can use the python "lambda" function, which gives you an anonymous function that is taken as a command for a button and handles the code running itself. After testing this fix, I wrote the corresponding "command = lambda: move(floor_number)" for each of the eight yellow buttons, and it turned out to work just fine.
 Then came the actual programming of the buttons, the genuine "coding" of not the structure, or the style, but the back-end functioning
of the interactions of the user with the buttons. To make this work, I used three main parts: a variable depicting the current floor in
which the elevator is, a variable to determine whether the elevator is moving or not, and a move() function that moves the elevator a
certain amount of distance depending on which floor the user wants to get to.
Then came the actual programming of the buttons, the genuine "coding" of not the structure, or the style, but the back-end functioning
of the interactions of the user with the buttons. To make this work, I used three main parts: a variable depicting the current floor in
which the elevator is, a variable to determine whether the elevator is moving or not, and a move() function that moves the elevator a
certain amount of distance depending on which floor the user wants to get to. Inside the move() function, I used the "moving" variable to state that the function can only perform operations when the elevator has stopped moving or hasn't started moving. Then, I used the "current_floor" variable and compared it to the function's parameter (the user's desired floor) to determine whether the elevator is going to move upwards or downwards. I calculated the number of floors that the elevator has to move in order to get to the user's desired floor and started the operation: The "moving" variable is set to 1 to determine that the elevator is now moving, and then a simple for loop takes care of the actual moving of the elevator drawing in the GUI to the desired floor. At the end of the process, the "moving" variable is set back to 0 to state that the elevator has stopped movement, and the "current_floor" variable is updated to the floor number that the elevator is now in.
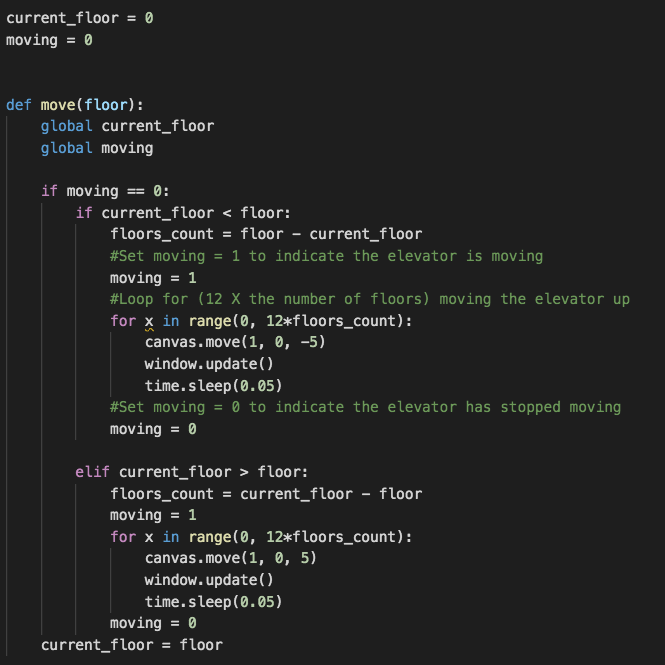 Finally, at the end of the program, we write the line "mainloop()" to allow the tkinter window to run in real time:
Finally, at the end of the program, we write the line "mainloop()" to allow the tkinter window to run in real time:
 This project was simple yet very fun to develop and definitely useful to get my head around the basic functions of animation and
graphical user interfaces in python. The code is a bit messy (specially due to all the sketching of the lines and shapes
in the coordinates of the window), and I'm sure there is a lot of room for optimization, but for a first run with Tkinter, I am
pretty happy with how it turned out to look and work. Who knows? I might get back to the project later and give it an upgrade.
This project was simple yet very fun to develop and definitely useful to get my head around the basic functions of animation and
graphical user interfaces in python. The code is a bit messy (specially due to all the sketching of the lines and shapes
in the coordinates of the window), and I'm sure there is a lot of room for optimization, but for a first run with Tkinter, I am
pretty happy with how it turned out to look and work. Who knows? I might get back to the project later and give it an upgrade. Until Next Time, this was Elevator.
